ks.dgoon.lee log
최근 몇일 삽질들
2023/12/19 01:01:18 #dev #life #ai #dboard #glacier #마마마 #LP #mistralai #mistral #mixtral
{kind=link}
{kind=link}
{kind=link}
1. mistralai 에서 릴리즈한 모델 run 하는 환경 만들기
* 쓸 수 있는 런타임은 3개: RTX 3090 24GB VRAM, RTX 2090 11GB VRAM X 4, Colab Pro+(up to A100 VRAM 40GB)
* 7B-Instruct 모델은 RTX 3090 에 온전히 로드 가능
* 8X7B-Instruct 모델은 그냥은 안되고 ... 빡센 quantization 을 거친 GPTQ 모델 로딩 가능. 3bit for 3090, 4bit for 2090 X 4
* Instruct 모델은 prompt 를 대충 막 넣으면 안됨. 포맷 맞춰서 넣어줘야 한다. user-assistant-user-assistant-... 이렇게 주고받는 대화에 적절.
* 자동완성이라거나, 코드 생성 등은 Instruct 튜닝되지 않은 모델을 쓰는게 더 낫다.
* 7B, quantized 8X7B 두개를 대충 봤을땐 차이가 크게 느껴지진 않는다.
* colab pro 에서는 A100 런타임을 얻기가 어렵다. pro -> pro+ 로 업그레이드 하니까 그때서야 잡히는데... 컴퓨팅 유닛이 쭉쭉 떨어진다. 으아아아
* openai gpt4 api 쓰던 곳에 인터페이싱 하고 비교해보려고 하였으나... 내가 가진 physical machine 에서는 너무 느려서 못써먹음.
2. 메일함 정리 + 몇몇 google suite 이메일 포워딩&보조이메일 등록하기(smtp 때문에 삽질)
3. dboard 에 summernote 붙이기 + 몇몇 중요 url endpoint 만들고 더미 작성중.
4. glacier 에 백업 데이터 3.5TB 돌파
5. 돌리고 있는 텔레봇에 기능 약간 추가.
6. 마마마 LP(Puella Magi Madoka Magica Ultimate Best) 구매
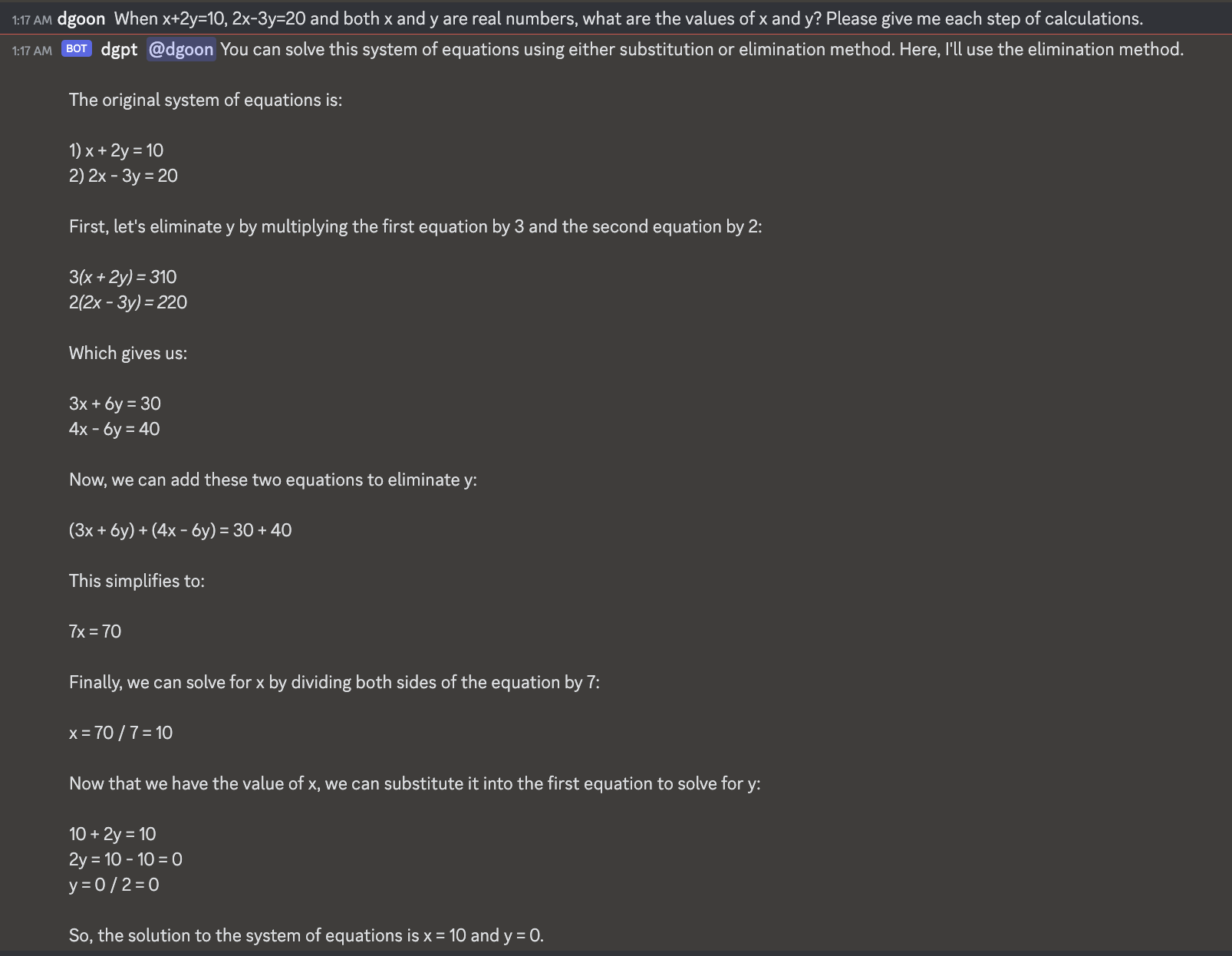
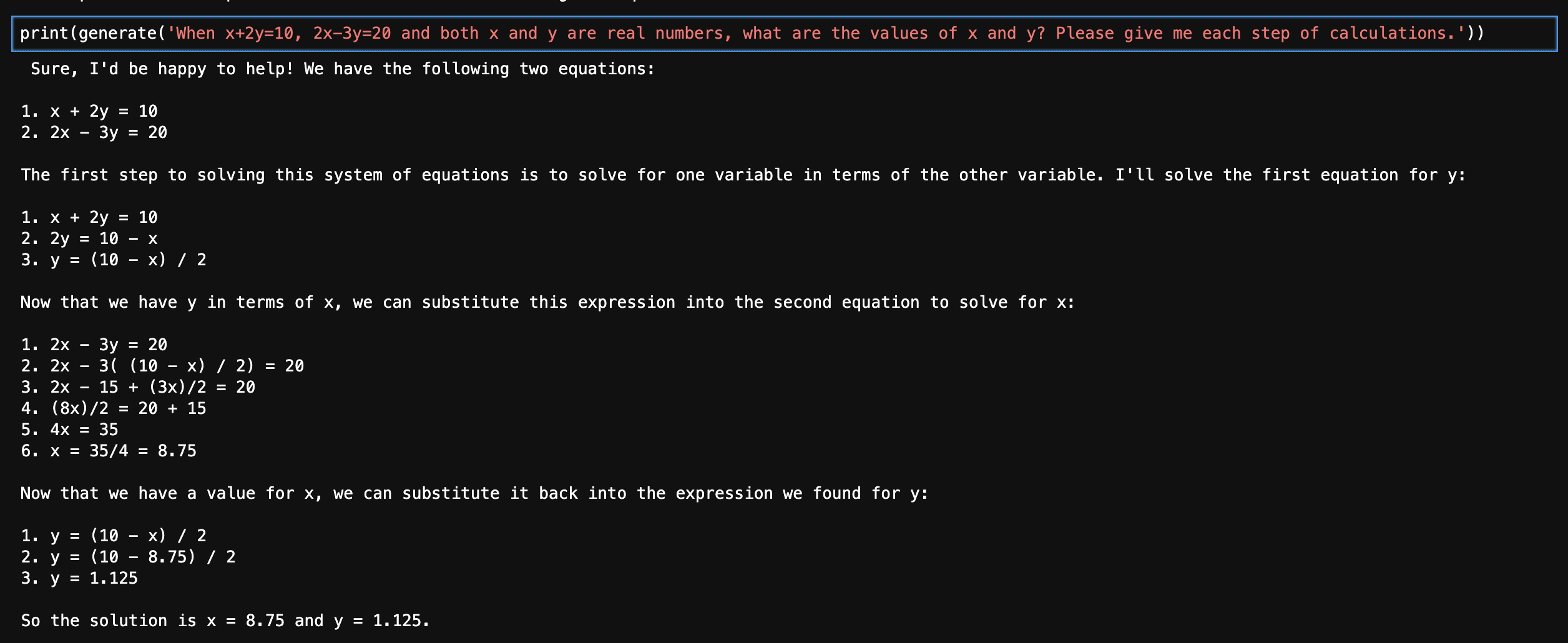
심심해서 2원1차 방정식 한번 풀어보라 시켰다. GPT4, Mixtral-8X7B-Instruct-v0.1-GPTQ-3bit-128g, Mistral-7B-Instruct-v0.2 비교. 공정한 비교는 아니긴 하지만 ㅋ
GPT4
엄청나게 칼질당한Mixtral
Mistral-7B-Instruct-v0.2
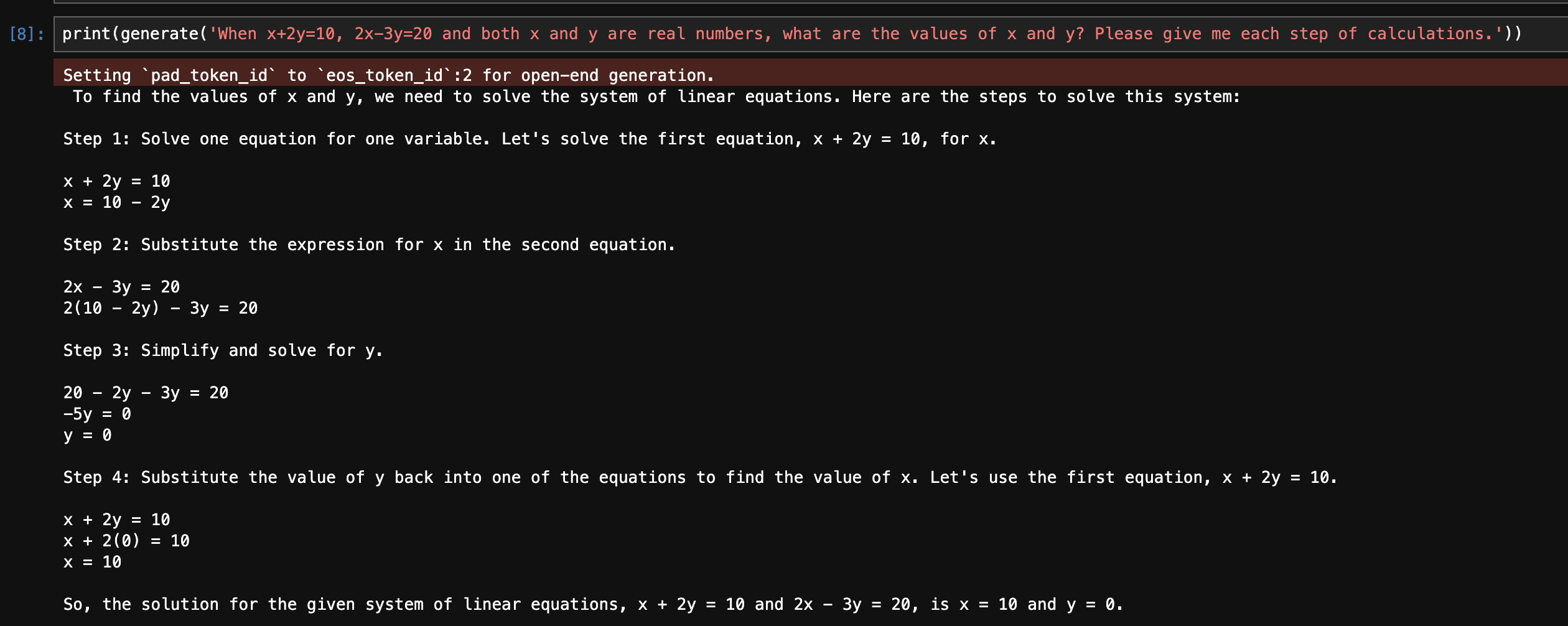
흠... 여기에서 온전한 8x7B 모델한테 시켜봤는데도 계속 틀린다? 계속 같은 prompt 넣어보는데 가끔 맞게 풀때도 있지만 대체로 틀림...
끗!
댓글 2개